On-demand AI-native engineers
Plank trains and embeds forward-deployed engineers into technical teams that need to build, deploy, and validate production AI faster than they can hire.
Powering AI engineering at

Integration infrastructure for AI agents.
$25M Series A · Lightspeed

An AI agent that generates thousands of edge-case network tests.
10M+ downloads

LLM kernel optimization and benchmarking platform.
$15M · Touring Capital · AGI House

Browser infrastructure for AI agents and web automations.
Y Combinator

AI-native engineering intelligence platform.
$25M raised

AI risk platform for fraud and compliance.
$145M raised

Computer-vision site safety: worker ID, geofencing, and PPE detection.
Public · NYSE: PCOR

AI code review for engineering teams.
Backed by Mayfield

AI equipment sourcing, from a team that has managed $5B+ in equipment.
$5.1M seed · The Westly Group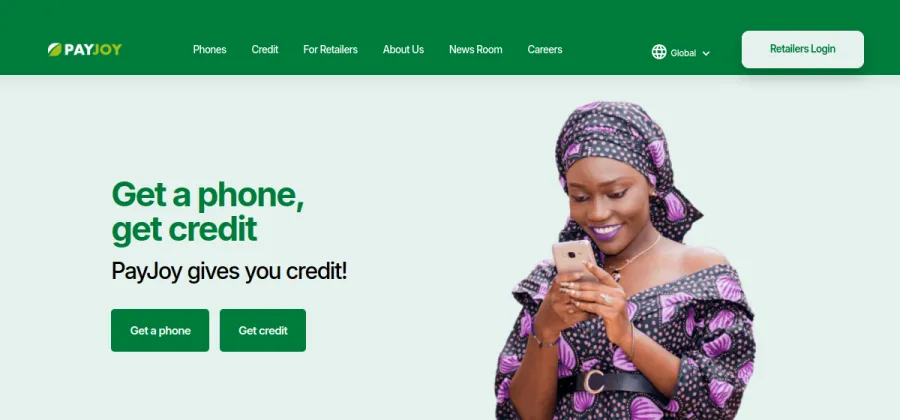

AI-powered credit-risk underwriting engine.
$400M+ raised

Enterprise gateway for the Model Context Protocol.
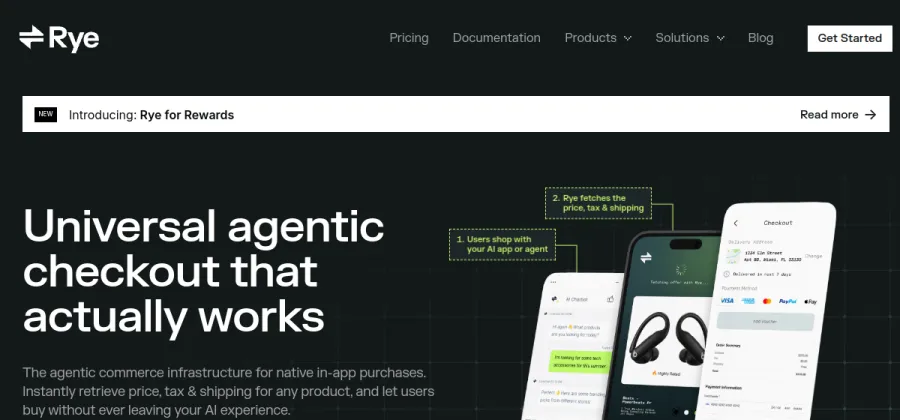

Universal Checkout API for agentic commerce.
$14M seed · a16z crypto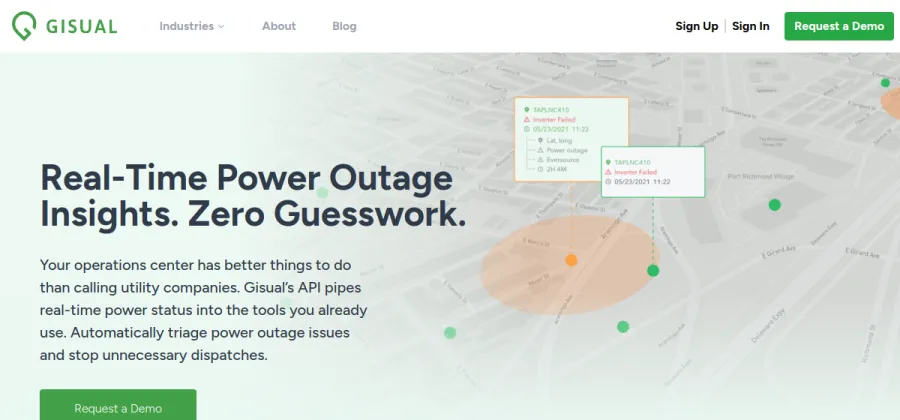

Real-time power-outage intelligence API.
 DeepTune
DeepTuneGenerative voice and dubbing engine.
$46M Series A · a16z

Agent infrastructure and open-source security.

An LLM pipeline turning coaching calls into real-time plan updates.


A high-throughput sensor pipeline for industrial automation.

Software for smart electrical panels and home energy.
$200M+ raised

IoT cold-chain logistics for temperature-controlled shipping.
$14M raised · Lowercarbon

Voice AI and high-accuracy OCR for medical forms.


An AI financial co-pilot.

AI diligence connecting climate companies with credit.

Custom expansion models for brands like McDonald’s, Sweetgreen, and Chipotle.

Vertical SaaS commerce platform for grocers.
Y Combinator (W23)

AI-powered notebook for frictionless capture.
$10M+ seed · First Round
 Achaemenid
AchaemenidConnected medical-device companion platform.


AI-powered multiomics aging engine.

Universal AI-agent platform & protocol.
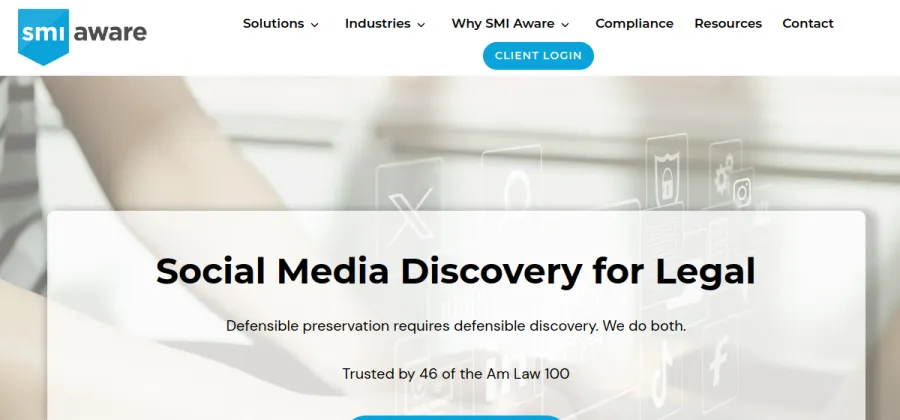

Legally defensible social-media discovery engine.
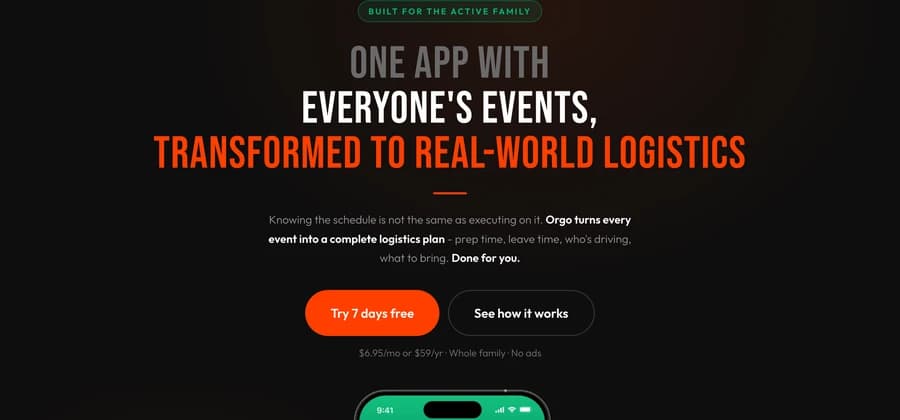

Logistics calendar for active families.
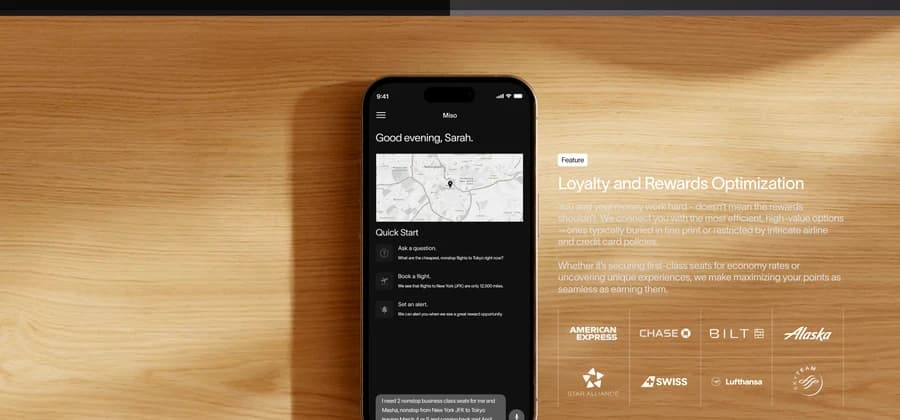
 Miso
MisoAgentic AI travel platform for frequent flyers.
$2M · Valar Ventures, Adjacent

Agentic AI for business-process operations.
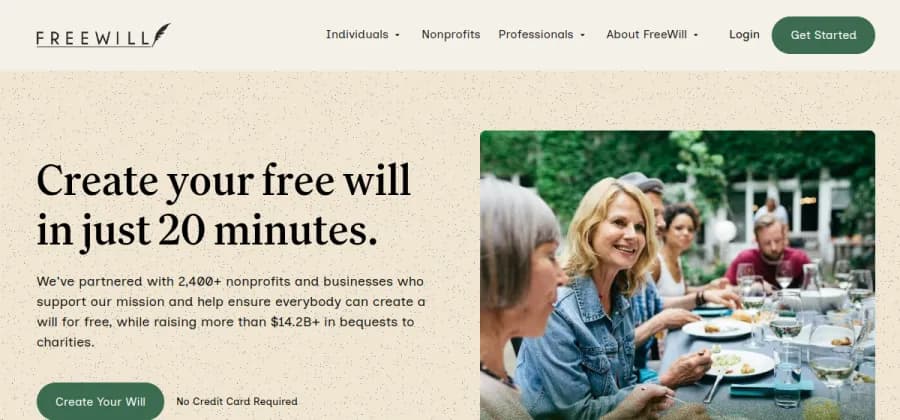

Online estate-planning platform.


On-device voice-isolation ML.
$6M raised
 ManufactureAI
ManufactureAIGenerative-AI tooling for hardware manufacturing.


AI ‘Intelligent Companion’ for seniors.
 Check Pilot Pro
Check Pilot ProDigital flight-training platform.


AI-powered market intelligence for systemic investing.

AI pricing engine for NetSuite.

AI operating layer for biopharma drug programs.
$4M · SK Networks
Proven across 50+ AI companies
Plank FDEs are shipping production AI across the sectors that matter.
Developer tools
Building agent infrastructure at Near AI, led by a co-author of “Attention Is All You Need,” and AI code review at Entelligence.
Construction
Shipping production AI at Procore (NYSE: PCOR), the platform behind 3M+ construction projects in over 150 countries.
Cybersecurity
Embedded with OpenVPN, the private-networking leader securing 20,000+ businesses and 4 million users.
Fintech
AI financial co-pilots and climate-credit diligence with Prosperity, PayJoy, and Ezra Climate.
Healthcare
Voice AI for Spanish-speaking patients at Rosette Health, and AI coaching trusted by Stanford and Duke Medicine at Fitmate.
Retail
Custom expansion models at RDP for brands like McDonald’s, Sweetgreen, and Chipotle.
Manufacturing
Industrial process AI at Procense, and equipment sourcing at Diagon, built by a team that has managed $5B+ in equipment.
Energy & hardware
Smart-panel energy software with Span.io, and IoT cold-chain logistics with Artyc.
One execution system
Build, deploy, and validate production AI
One embedded team that builds your AI products, deploys them into your customers’ systems, and validates every release, vendor-neutral across OpenAI, Anthropic, and open models.
The Plank AI Accelerator
How Plank develops AI-native engineers
Every Plank engineer is developed through the Plank AI Accelerator, hands-on training in the realities of production AI work: agents, RAG, customer deployment, modern AI tooling, and high-quality engineering habits, then embeds with pod-mates they have already shipped with.
Agentic dev workflow
Shipping with Claude Code + Codex
AI applications
LLM features and products, end to end
Agents & retrieval
Multi-agent systems and RAG
Voice & multimodal
Real-time voice and video AI
Production & deployment
Shipping, monitoring, and reliability
Forward deployment
Customer integration and rollout
Every cohort trained and every team embedded makes the next deployment faster.
Inside the Plank AI AcceleratorHow we ship
Harness-driven SDLC
Plank engineers steer a pool of AI agents through a controlled harness, so a small pod ships like a much larger team, with review, QA, and safe deploys built into every pull request.
AI pair-coding
Engineers steer Claude Code and Codex on every feature while the agents do the typing.
- Small, frequent PRs against main
- The engineer reviews and merges every diff
Conductor + worker pool
A conductor drafts the spec and hands work to a pool of agents running in parallel.
- Each agent works in its own clone
- The conductor never edits code, git is the audit log
Quality, woven in
Nothing reaches production unreviewed or untested, quality is built in.
- Cross-model review + manual QA on every PR
- Per-feature blue/green deploys, with fast rollback
Built for production AI from day one
Plank engineers start the same day, stay vendor-neutral, and arrive as a pod that has already shipped together.
Start the same day
Plank engineers embed and start the same day, then ship to production in days, speed of engagement and speed of delivery from the first call, while hiring the same role typically takes two to four months.
Vendor-neutral
Plank engineers work across OpenAI, Anthropic, and open models, so your architecture stays yours.
Trained for production AI
Every engineer is developed in the Plank AI Accelerator, hands-on training in agents, deployment, and modern AI tooling, then embeds with pod-mates they have shipped with before.
Inside the Plank AI AcceleratorYour IP, your repos
NDAs by default, your code in your repositories from day one, and clean IP assignment. Your architecture and your IP stay yours.
Put an embedded AI team on your roadmap
Forward-deployed engineers to deploy, AI-native engineers to build, and on-demand QA pods to validate, embedded with your team, starting the same day.