LangGraph templates to solve the ARC-AGI-3 benchmark
We partnered with the ARC Prize team to build and open-source a LangGraph starter agent: a stateful, multi-agent template that learns to solve LS20, the first game in the ARC-AGI-3 reasoning benchmark. Rather than hardcoding rules, it combines memory, vision, planning, and spatial reasoning inside a multi-agent graph, so it can adapt to a new environment.
By Sophia Willows and Anusheel Bhushan
Benchmark
ARC-AGI-3
Game
LS20
Framework
LangGraph
Code
Open-source
Why ARC-AGI-3 matters
Traditional AI benchmarks are static: they test against a fixed dataset with predetermined answers. ARC-AGI-3 is different. It is the first large-scale Interactive Reasoning Benchmark, dropping an agent into a dynamic environment with no prior instructions and asking it to work the rules out for itself.
To do that, an agent has to demonstrate five core capabilities:
- Exploration
- Percept, plan, action
- Memory
- Goal acquisition
- Alignment
The benchmark will span roughly 100 unique environments. Success depends on how quickly an agent acquires new skills and generalizes to tasks it has never seen, not on memorization.
The game: LS20
LS20 looks simple and is not:
- A locked door opens only when the key you are holding matches its shape.
- Moving across a rotator cycles your held key through different shapes.
- Every move costs one health point, so exploration is not free.

Why LangGraph
We chose LangGraph because it enables stateful, multi-agent workflows: graph-based systems where agents collaborate dynamically while holding state across long executions. The decisive advantage is that LangGraph graphs are code, so a supervisory agent can modify the workflow at runtime. That is exactly what a recursively self-improving system for ARC-AGI-3 needs.
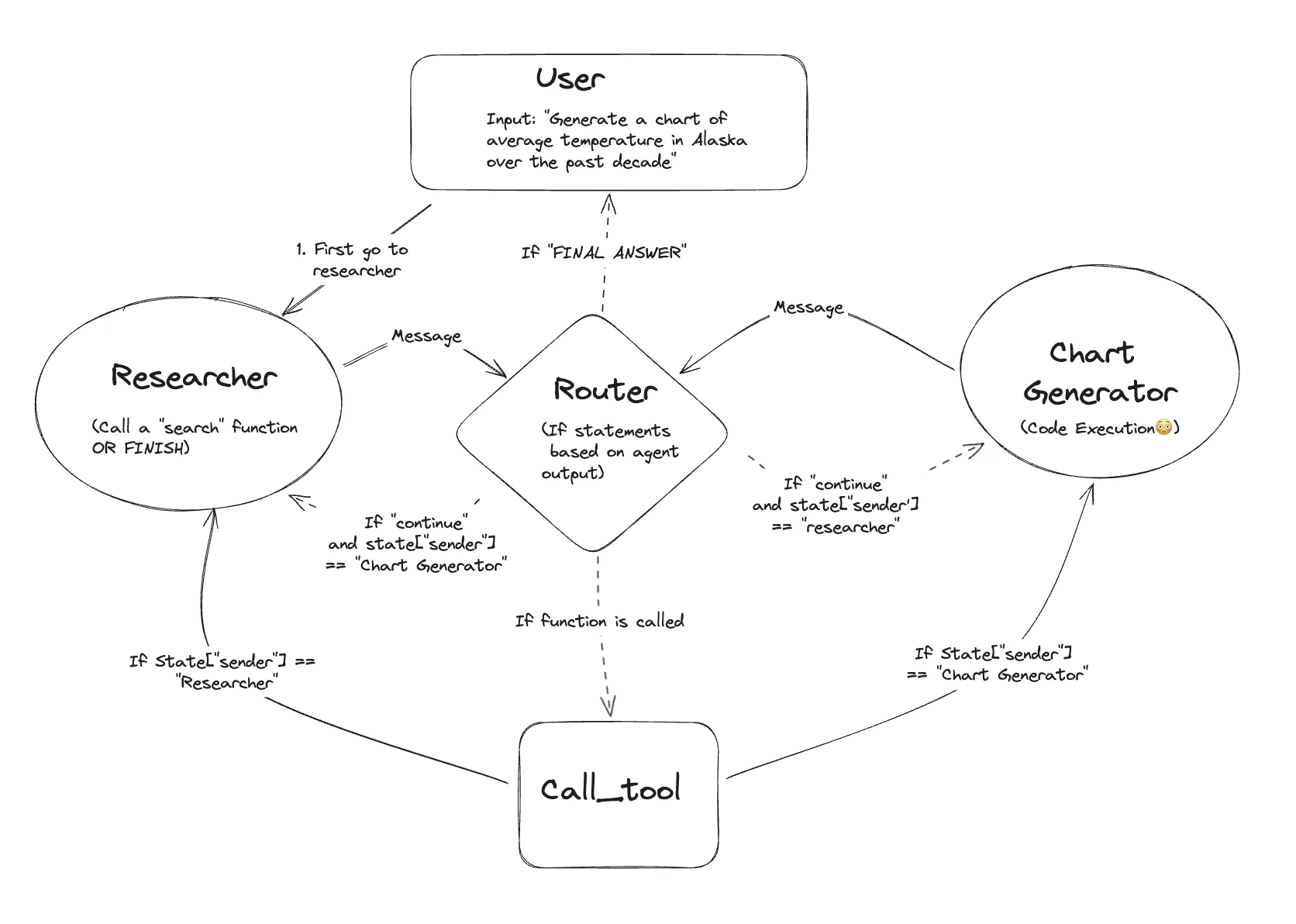
How we built it
Memory.The agent uses a three-tier memory system. Short-term memory, inspired by Claude’s think tool, lets it reflect on immediate observations. Long-term memory is persistent SQLite storage through LangGraph’s SqliteStore. An observation journal holds the agent’s own notes about game mechanics, loaded back into the system prompt, with tools to think, observe, and delete observations as its understanding improves.
Vision.Frames arrive as multi-dimensional JSON arrays, where positions are coordinates and values are colors. We render them with Python’s Pillow using a higher-contrast palette, compare each frame against the previous one to detect changes, and highlight the important elements, an approach inspired by Browser Use. This delta tracking let the agent recognize player movement without a dedicated pathfinder.
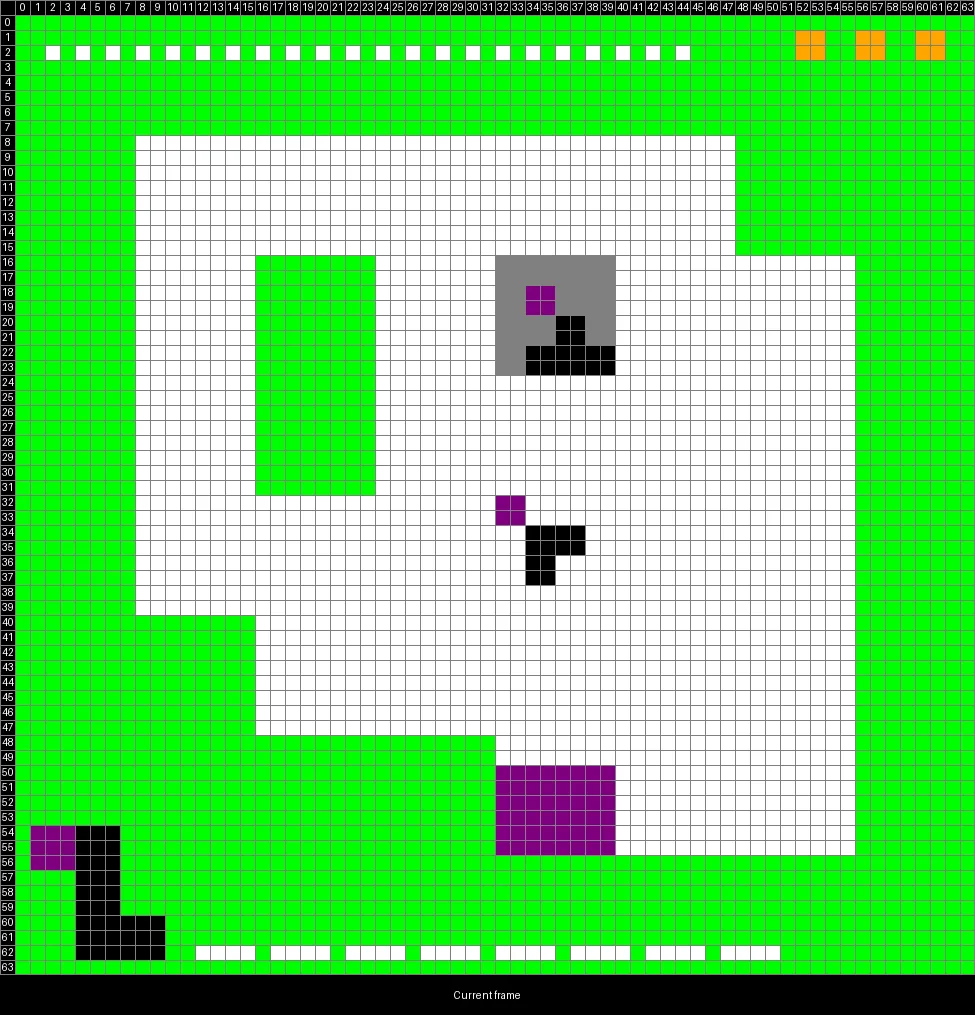
Planning. The agent first struggled to infer the overall goal, so we gave it context in the system prompt:
- Reach the door while holding the correct key.
- Your held key is shown in the bottom-left corner.
- Green elements are walls.
- Rotators change your key when you collide with them.
Spatial reasoning.A dedicated LangGraph node compares the player’s key shape against the door’s requirement. Pathfinding started as hardcoded A*, then we replaced it with general-purpose delta tracking, where a multimodal model reads frame changes directly. That shift is what moves the template toward generalizing across different games, such as FT09, a tile-clicking game with entirely different mechanics.

The result
The agent solved the first level of LS20 in an optimal number of moves. It recognized it was holding the wrong key, pathed straight to the rotator to swap, then went to the door once the correct key was in hand.
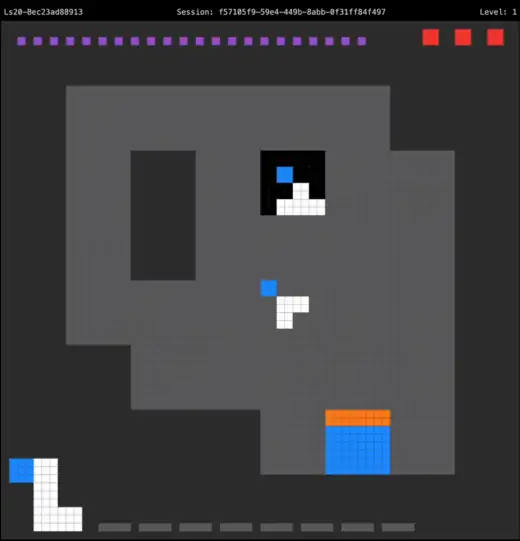

The second level, which requires strategic health management and multiple rotator uses, is left unsolved by the current template, an open extension point for the community to build on.
The takeaway: spatial reasoning, combined with a few prompt hints about the environment, is enough to get this far. The approach balances scaffolding with learned competence rather than chasing a pure zero-shot solution.
Open to contributions
Building systems that can learn and adapt their own problem-solving approach is one of the most exciting frontiers in AI. We built the agent with the ARC Prize team and open-sourced it as the LangGraph thinking agent partner template, so the community can build on it through the ARC-AGI-3 Agents toolkit.
References
Put an embedded AI team on your roadmap
Forward-deployed engineers to deploy, AI-native engineers to build, and on-demand QA pods to validate, embedded with your team, starting the same day.